
This week we have released the first beta of Astro 5, which includes a whole new way to handle content in Astro. This post takes a deep dive into the Content Layer API, showing how it works and how you can use it to build your sites.
Astro was born to create content-driven websites. While it can now be used to build all sorts of dynamic apps too, it is still the very best for sites that are built around lots of content. From full-featured docs sites built with Starlight like Cloudflare and StackBlitz, to beautiful marketing sites for brands such as Porsche and Netlify, millions of users every day are already appreciating the fast and accessible sites that you can build with Astro, and thousands of engineers love the best developer experience in the industry.
In Astro 2 we introduced Content Collections as a powerful new way to organize your local content, build with type safety, and scale to thousands of pages. Content Collections provide a best-in-class developer experience for local files such as Markdown and MDX, but we heard from you that you wanted the same benefits for all of your content including remote APIs. It was also clear that while many people were building sites with thousands of pages, our Content Collections API struggled to scale into the tens of thousands of pages, with slower builds and excessive memory usage.
In June we shared an early preview of our plan to solve these problems and more with an all-new type of content collection backed by the Content Layer API that gives you the flexibility you asked for. We imagined taking collections beyond just files in src/content and letting you load your content from anywhere. We have been testing with collections that scale up to a size never before possible. From our first experimental release in Astro 4.14, we have been hard at work stabilizing this new API for release in Astro 5.
What is the Content Layer
The Content Layer API is the future of the content collections you know and love. It allows you to load data from any source when you build your site, and then access it on your page with a simple, type-safe API.
The Content Layer API doesn’t care where your data is stored. One collection could still be local Markdown files, another could call an API, and yet another could live elsewhere on your filesystem. Using the same getEntry() and getCollection() functions as before, you can load data from many sources on the same page. There’s no performance hit: Astro caches the data locally between builds, meaning that updates can be fast and can minimize the number of API calls that need to be made. And of course, everything is still type-safe, with TypeScript types auto-generated from your schema.
If you’ve used content collections before, you’ll recognize many of the following concepts and terms. In fact, we haven’t changed much about using collections in your project at all! A collection is still our term for a set of entries that share a common schema. Each entry has a unique ID. It is analogous to a table in a relational database.
But now, each collection uses a loader, which defines how the entries are loaded to populate that collection. A loader can be a basic inline function that returns an array of entries, or it can be a more advanced object that handles its own caching and data store. The very first loaders are already distributed as modules on npm.
Whenever your site is built, the loader for each collection is invoked which then updates the local data store. You can query that data store using the familiar getCollection() and getEntry() functions. This is done at build time for your prerendered pages, or during server rendering if using an on-demand adapter. In each of these cases, the same data is available, which is the snapshot from the time of the build.
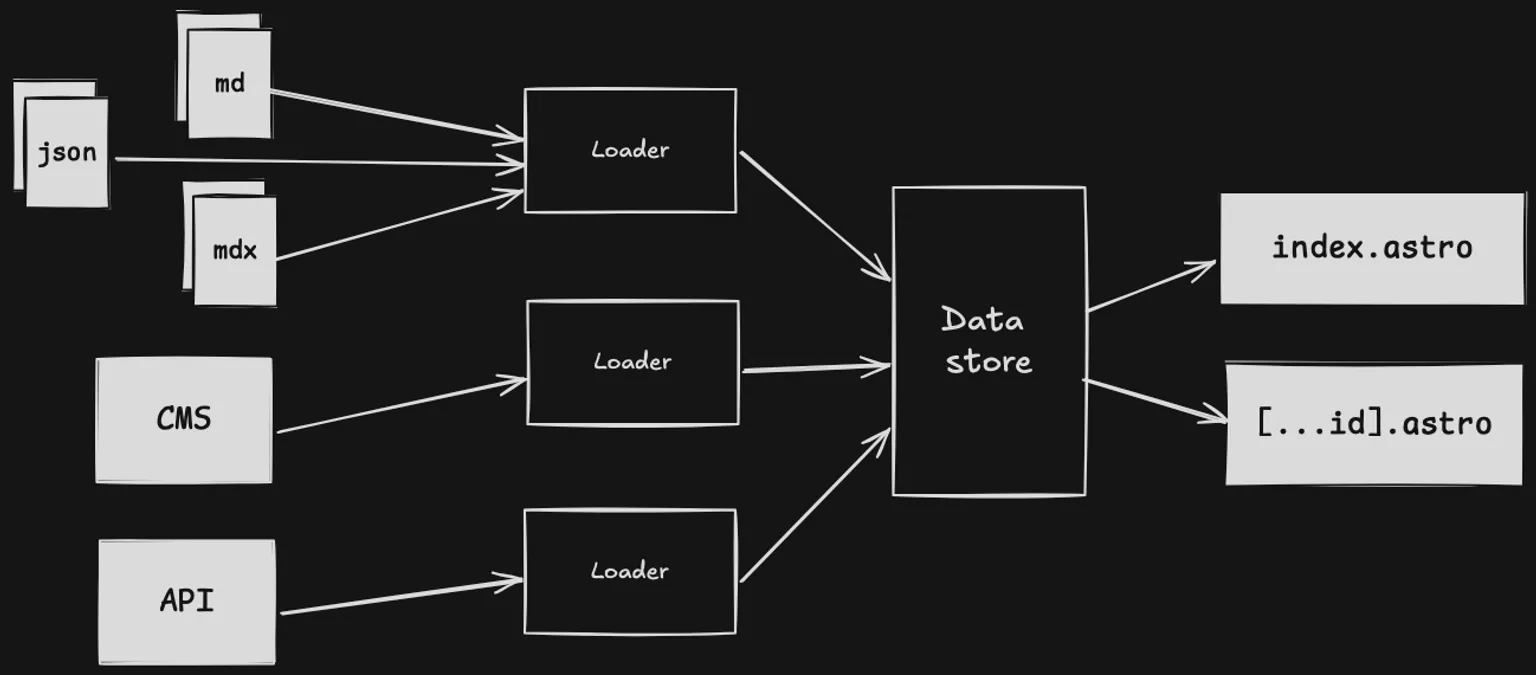
Creating collections
Define your content collections in src/content/config.ts, which you already have if you’ve used collections before. The new loader property defines the source of the data, and can be as simple as an async function that returns an array of items:
import { defineCollection, z } from 'astro:content';
const countries = defineCollection({ loader: async () => { const response = await fetch('https://restcountries.com/v3.1/all'); const data = await response.json(); // Must return an array of entries with an id property, or an object with IDs as keys and entries as values return data.map((country) => ({ id: country.cca3, ...country, })); }, // optionally define a schema using Zod schema: z.object({ id: z.string(), name: z.string(), capital: z.array(z.string()), population: z.number(), // ... }),});
export const collections = { countries };This data is then available in your .astro components, just like before:
---import type { GetStaticPaths } from 'astro';import { getCollection } from 'astro:content';
export const getStaticPaths: GetStaticPaths = async () => { const collection = await getCollection('countries'); if (!collection) return []; return collection.map((country) => ({ params: { id: country.id, }, props: { country, }, }));};
const { country } = Astro.props;---
<h1>{craft.data.name}</h1><p>Capital: {craft.data.capital}</p>We were already pretty pleased with this experience of querying and rendering your data on the page, so we turned our attention to the mechanics underlying the process. Let’s take that deep dive into how the Content Layer API organizes, manages, and uses your content!
Content layer lifecycle
When astro build or astro dev is run, the loader for each collection is invoked in parallel. These loaders update their own scoped data store, which is preserved between builds.
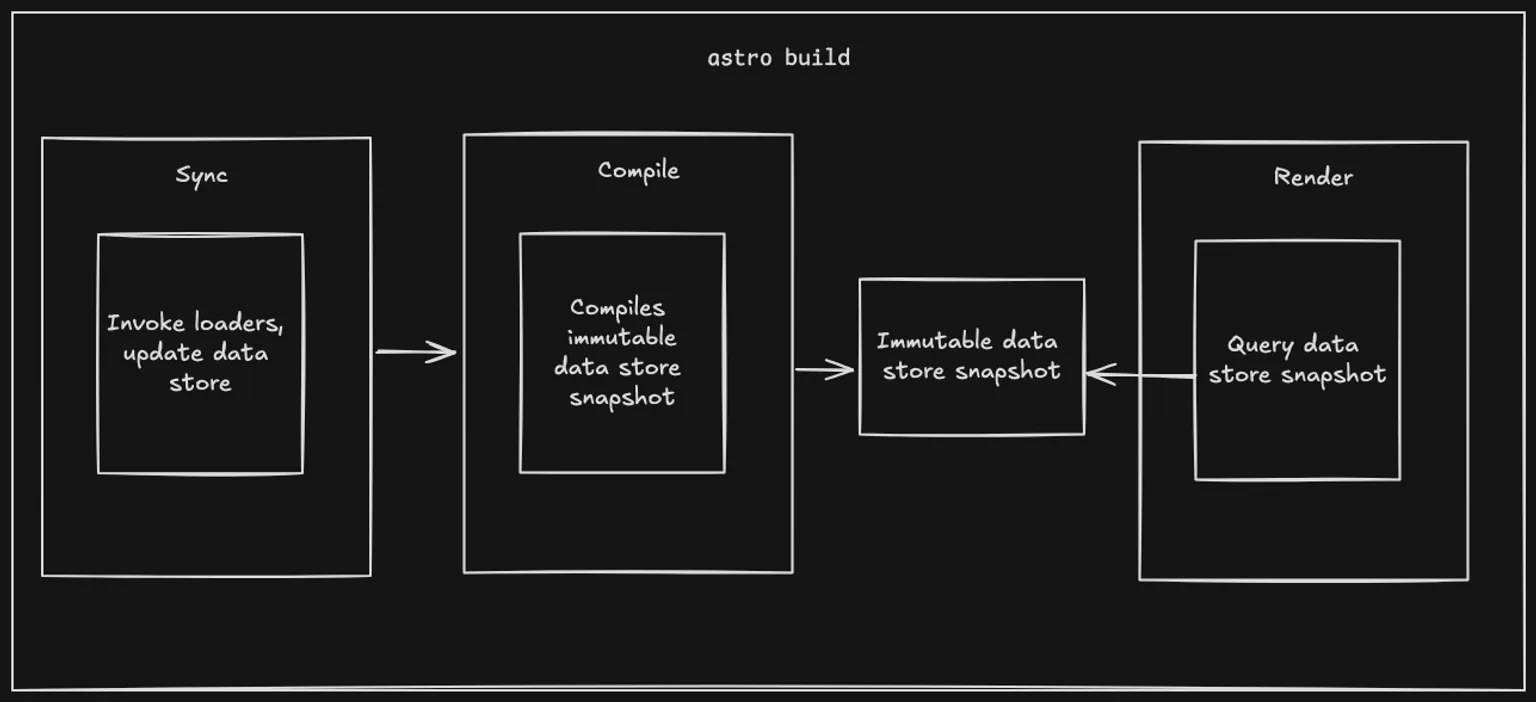
Astro components and pages can then use getCollection or getEntry to query the data. The data is immutable at that point, so the pages are all querying the same snapshot, compiled at build time. This applies whether the page is being prerendered at build time, or server rendered on-demand. The important thing to note here is that the data store is only updated at build time: a deployed site cannot change the data store. If a data source needs to update a collection it must do this by triggering a new build.
Although immutable in production, when running astro dev the data store can be updated on demand by users with the s+enter hotkey, or by integrations. They can do this in many ways, such as registering a development refresh endpoint or opening a socket to a CMS to listen for updates.
How a loader works
The first example showed how to build a simple inline loader, but you don’t need to stop there. With the object loader API, you can make powerful loaders with more advanced capabilities. An object loader interacts with the content layer via a data store object. This is a key-value store that is scoped to an individual collection. A collection can only access its own entries but has complete control over these. If a loader knows that its data source hasn’t changed then it can skip updating entirely, or it can just update the entries which have changed.
The Content Layer API provides some tools to make this easier. First is the metadata store, which can be used to store arbitrary values such as “last modified” times, or sync tokens. Comparing these will allow the loader to do things like make conditional API requests, or use delta sync APIs.
This example shows how to do this with an RSS feed loader. It stores the last modified header in the metadata store and then uses it to make conditional requests when it next loads the feed:
export function feedLoader({ url }: FeedLoaderOptions): Loader { const feedUrl = new URL(url); // Return a loader object return { // The name of the loader. This is used in logs and error messages. name: 'feed-loader', // The load method is called to load data load: async ({ store, logger, meta }) => { // Check if there's a last-modified time already stored const lastModified = meta.get('last-modified');
// If so, make a conditional request for the feed const headers = lastModified ? { 'If-Modified-Since': lastModified } : {};
const res = await fetch(feedUrl, { headers });
// If the feed hasn't changed, you do not need to update the store if (res.status === 304) { logger.info('Feed not modified, skipping'); return; } if (!res.ok || !res.body) { throw new Error(`Failed to fetch feed: ${res.statusText}`); }
// Store the last-modified header in the meta store so we can // send it with the next request meta.set('last-modified', res.headers.get('last-modified'));
// ... now store the data }, };}If the content has changed, we can either clear the store and replace it all, or incrementally update individual entries if the data source provides this level of detail.
export function feedLoader({ url }: FeedLoaderOptions): Loader { const feedUrl = new URL(url); // Return a loader object return { // The name of the loader. This is used in logs and error messages. name: 'feed-loader', // The load method is called to load data load: async ({ store, logger, meta }) => { // Check if there's a last-modified time already stored const lastModified = meta.get('last-modified');
// If so, make a conditional request for the feed const headers = lastModified ? { 'If-Modified-Since': lastModified } : {};
const res = await fetch(feedUrl, { headers });
// If the feed hasn't changed, you do not need to update the store if (res.status === 304) { logger.info('Feed not modified, skipping'); return; } if (!res.ok || !res.body) { throw new Error(`Failed to fetch feed: ${res.statusText}`); }
// Store the last-modified header in the meta store so we can // send it with the next request meta.set('last-modified', res.headers.get('last-modified'));
const feed = parseFeed(res.body);
// If the loader doesn't handle incremental updates, clear the store before inserting new entries // In some cases the API might send a stream of updates, in which case you would not want to clear the store // and instead add, delete, or update entries as needed. store.clear();
for (const item of feed.items) { // The parseData helper uses the schema to validate and transform data const data = await parseData({ id: item.guid, data: item, });
// The generateDigest helper lets you generate a digest based on the content. This is an optional // optimization. When inserting data into the store, if the digest is provided then the store will // check if the content has changed before updating the entry. This will avoid triggering a rebuild // in development if the content has not changed. const digest = generateDigest(data);
store.set({ id, data, // If the data source provides HTML, it can be set in the `rendered` property // This will allow users to use the `<Content />` component in their pages to render the HTML. rendered: { html: data.description ?? '', }, digest, }); } }, };}When not to use content collections
Previously it was clear when content collections were a good idea: whenever you were using local content in your pages! The Content Layer API gives you so much more power and flexibility because you can use it for any content source including live APIs. However, it’s important to remember that data is only updated when the site is built, so it won’t serve every use case.
This means that collections are perfect when your data changes relatively infrequently, such as a blog. If you’re writing a blog that’s hosted in a CMS, you can trigger a build with a webhook whenever you publish a new post. The content layer’s incremental updates should make this build fast.
The same applies to most e-commerce sites, where a build can be triggered when a product is edited. If you are ok with waiting for the time it takes to deploy the site to publish updates, then content collections are still your obvious choice. You will get the best performance and great developer experience.
If you need your pages to update in near real-time or with personalized content, then you are better off using an on-demand rendering adapter, ideally with CDN cache headers to ensure that page loads are super fast. You can even combine the two using server islands and get the best of both worlds - render the main content using content collections, and use a server island for real-time or personalized content.
What’s next
The Content Layer API is a big step forward for Astro, but we’re just getting started. Currently, the data store is just a key-value store, with limited filtering. This is fast but not memory efficient, and querying is not very flexible. Our goal is to introduce a backend based on Astro DB in a future version to help it scale to hundreds of thousands of pages. It will also allow us to support more complex queries, and perhaps even real-time updates.
In the meantime, we’d love to hear your feedback on the Content Layer API! Try migrating your existing sites to use it. (It’s easy, we promise!) and let us know how it goes. Try out some of the new loaders built by the community, or build your own for your favorite API. We’re excited to see what you build with it!